AMD Instinct MI300A APU Overview#
1. Introduction#
The AMD Instinct™ MI300A Accelerated Processing Unit (APU) represents a major architectural advancement in AMD’s Compute DNA (CDNA) portfolio. As AMD’s first fully integrated CPU+GPU APU designed for high-performance computing (HPC) and artificial intelligence (AI) workloads, the MI300A combines the power of Zen 4 CPU cores with CDNA3 GPU compute units and high-bandwidth HBM3 memory into a single unified package. This integration delivers significant benefits over traditional discrete CPU-GPU systems by eliminating performance bottlenecks & memory bandwidth bottlenecks, reducing data movement overhead, addressing programmability overhead, and the need to refactor code for new hardware generations.
The MI300A introduces a fully coherent, unified memory architecture, enabling CPU and GPU components to share data and cache efficiently, simplifying software development and improving runtime performance. By tightly integrating high-performance “Zen4” CPU cores with high-throughput GPU Compute Units (CUs) and 128GB of unified HBM3 memory into a single socket with hardware-supported cache coherence, the MI300A APU eliminates the data movement penalties commonly associated with discrete architectures. Through architectural innovations like shared last-level cache (LLC), cache-coherent memory access, direct CPU-GPU fabric interconnects, seamless task delegation across CPU and GPU, synchronization across compute domain, and support for hardware sparsity, MI300A is optimized to accelerate the convergence of HPC and AI at exascale.
These architectural innovations are supported by AMD’s ROCm™ open software platform, which provides a consistent programming model for heterogeneous compute. The result is a single-package solution that delivers exceptional energy efficiency, programmability, and performance density — enabling next-generation exascale systems to tackle converged HPC and AI workloads with reduced complexity and improved throughput.
This guide provides a comprehensive overview to GPU partitioning on MI300A APU platforms, focusing on supported compute partition modes, NUMA configurations or memory access models, system configuration requirements, and usage guidance. Whether for virtualized multi-tenant environments or tightly coupled HPC workloads, the MI300A’s partitioning features empower developers and administrators to tailor resource allocation for optimal system utilization. This guide also includes validation and troubleshooting guidance to help users leverage MI300A’s full potential on bare-metal deployments.
2. GPU Architecture Summary#
The MI300A APU architecture is built using AMD’s chiplet-based design principles and state-of-the-art 3D stacking technology, bringing CPU and GPU compute into a unified, high-bandwidth package. This architecture enables tight coupling between CPU and GPU resources while maximizing memory bandwidth and minimizing data latency.
Key architectural components include:
Accelerator Complex Dies (XCDs): - 6 XCDs per socket - Each XCD contains 38 CDNA3-based GPU Compute Units (CUs) - Total of 228 GPU CUs per socket
CPU Chiplets: - 3 chiplets with 8-core AMD “Zen4” CPU dies - Total of 24 CPU cores per socket - CPU and GPU share a unified memory address space and a large Last Level Cache
HBM3 Memory: - 8 x 16GB HBM3 stacks per socket - 128GB of total unified HBM capacity - Host memory and I/O buffers are fully interleaved across all 8 HBM stacks
Last Level Cache (LLC): - 256 MB of shared last-level cache (LLC) per socket by both CPU and GPU clients - Sits beyond the coherence point; access does not require cache probing or flushes
Infinity Fabric: - High-bandwidth, coherent interconnect fabric connecting all compute elements - Enables 2-socket (2S) and 4-socket (4S) fully connected node configurations - Supports remote memory access and GPU virtualization
Sparsity Acceleration: - Hardware-level 2:4 sparsity support to accelerate AI workloads - Efficient handling of sparse matrix operations to save compute cycles and memory
Partitioning Modes: - SPX (Single Partition): All 6 XCDs are grouped into one partition - CPX (Core Partitioned): Each XCD is treated as a separate partition, yielding 6 partitions per socket
NUMA Mode: Memory partitioning modes that define how HBM is allocated and accessed by logical devices - NPS1 (NUMA Per Socket): Data is uniformly interleaved across all HBM stacks - Fixed at boot time and not dynamically configurable
Unlike MI300X, MI300A does not support discrete DDR DIMM access, and all system memory is resident within the 128GB HBM. This ensures high memory bandwidth and simplifies data placement for unified CPU-GPU workloads. Both 550W air-cooled and 760W liquid-cooled configurations are supported, making MI300A suitable for diverse datacenter environments.
This architectural design provides the foundation for software-defined partitioning and workload orchestration — enabling MI300A to deliver balanced compute, memory, and I/O performance for the next era of converged HPC and AI workloads.
3. Partitioning Concepts#
a. Compute Partitioning (SPX, CPX)#
Compute partitioning on the MI300A APU enables fine-grained resource management by dividing GPU compute resources into multiple logical devices, allowing users to optimize for workload isolation, parallel execution, and resource efficiency. Unlike discrete GPU solutions, the MI300A architecture unifies CPU, GPU, and memory into a single coherent address space backed by high-bandwidth HBM3. This allows partitioned workloads to share memory more seamlessly while benefiting from high interconnect bandwidth and cache coherence.
MI300A supports the following compute partitioning modes:
SPX (Single Partition X-celerator): All GPU XCDs are grouped as a single monolithic device.
CPX (Core Partitioned X-celerator): Each of the six XCDs is treated as a separate logical device.
All partitioning is managed at the driver level and can be reconfigured dynamically using utilities such as amd-smi. These modes enable flexible workload orchestration strategies ranging from unified execution (SPX) to strict isolation (CPX).
Key Benefits of Compute Partitioning:
Enables multi-tenancy and workload isolation.
Provides better scheduling granularity and performance tuning.
Optimizes resource utilization across mixed workloads.
Reduces contention and minimizes performance variability.
Partitioning Rules and Notes:
MI300A includes 6 GPU XCDs per socket; partitions must use physically grouped XCDs.
Each partition is assigned an equal number of Compute Units (CUs) and interleaved access to the unified HBM pool.
Partitioning is spatial (hardware-aware) and operates at the kernel driver level, independent of virtualization or container runtimes.
In MI300A only NPS1 (NUMA Per Socket) is available, where all HBM stacks are uniformly interleaved.
Mode |
Logical Devices |
CUs per Device |
Memory per Device |
Best For |
|---|---|---|---|---|
SPX |
1 |
228 |
128GB |
Unified workloads, large models |
CPX |
6 |
38 |
16GB |
Isolation, multi-user setups, fine-grained scheduling |
i. SPX (Single Partition X-celerator)#
Default Mode for MI300A platforms.
Combines all six XCDs into a single logical GPU device.
All compute and memory resources (228 CUs, 128GB HBM) are exposed as a unified pool.
Ideal for applications that require high memory bandwidth, unified addressability, and hardware-level synchronization.
Behavior:
amd-smireports a single GPU device.Workloads are automatically distributed across all six XCDs.
Unified Last Level Cache (LLC) and memory fabric ensure efficient inter-chiplet communication.
Optimal for single-user, large-batch, or monolithic workloads such as deep learning model training or HPC simulations.
ii. TPX (Triple Partition X-celerator)#
Divides the GPU into three partitions, each comprising two XCDs.
Exposes three logical GPU devices per socket.
Each TPX partition gets access to 76 CUs and approximately 32GB of interleaved HBM memory.
Use Case:
Balanced resource sharing across multiple jobs.
Good for parallel model execution where each model requires moderate compute and memory.
Enables concurrent scheduling of independent medium-sized workloads without over-provisioning.
Behavior:
amd-smireports three GPU devices.Each device can be targeted independently via HIP, OpenMP, or other ROCm-compatible programming models.
All partitions maintain full memory coherence and uniform memory access through NPS1.
iii. CPX (Core Partitioned X-celerator)#
Most granular mode of operation.
Each XCD is exposed as a distinct logical GPU device (6 devices per socket).
Each CPX partition includes 38 CUs and 16GB of interleaved HBM memory.
Excellent for scenarios requiring workload isolation or running multiple lightweight jobs concurrently.
Use Case:
Multi-User Environments: Allocate each CPX partition to different users or tenants to enforce hardware-level isolation.
Task Parallelism: Run multiple inference or small-batch training jobs simultaneously.
Fine-Tuned Scheduling: Better visibility and control over how jobs are assigned to physical resources.
Behavior:
amd-smireports six GPU devices.Each device operates as an independent compute target with full access to the shared memory fabric.
Peer-to-peer (P2P) access between CPX partitions is supported and can be enabled for collective operations.
CPX mode is particularly powerful in shared infrastructure environments or cloud-native workloads.
MI300A SPX |
MI300A CPX |
|---|---|
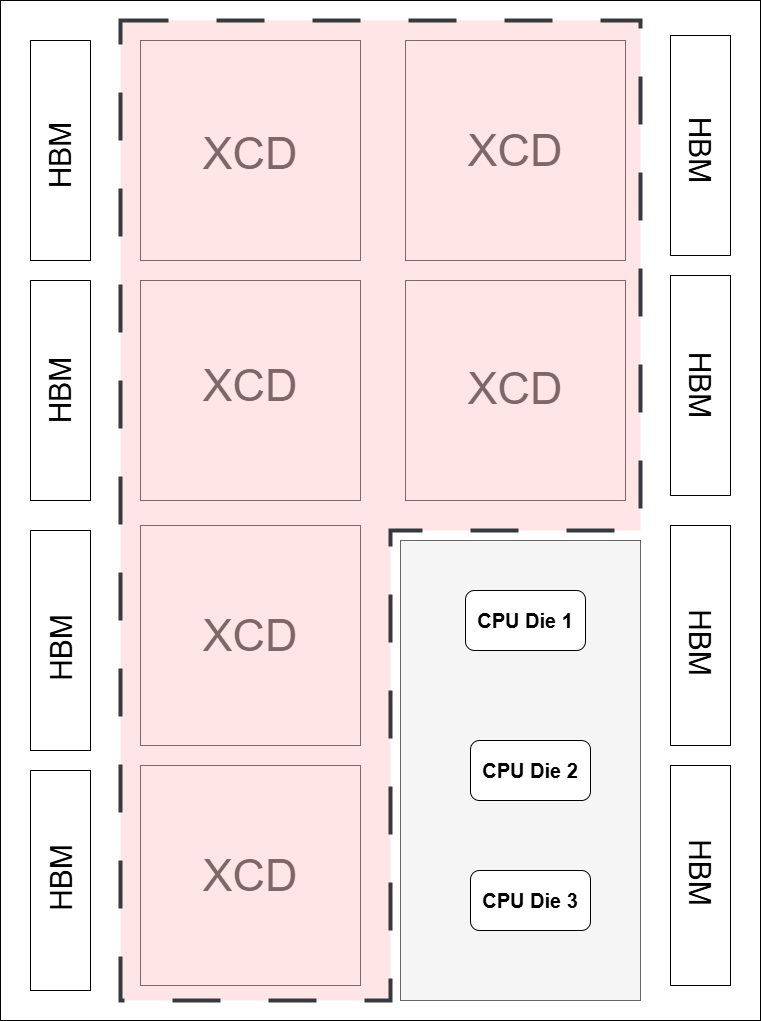
|
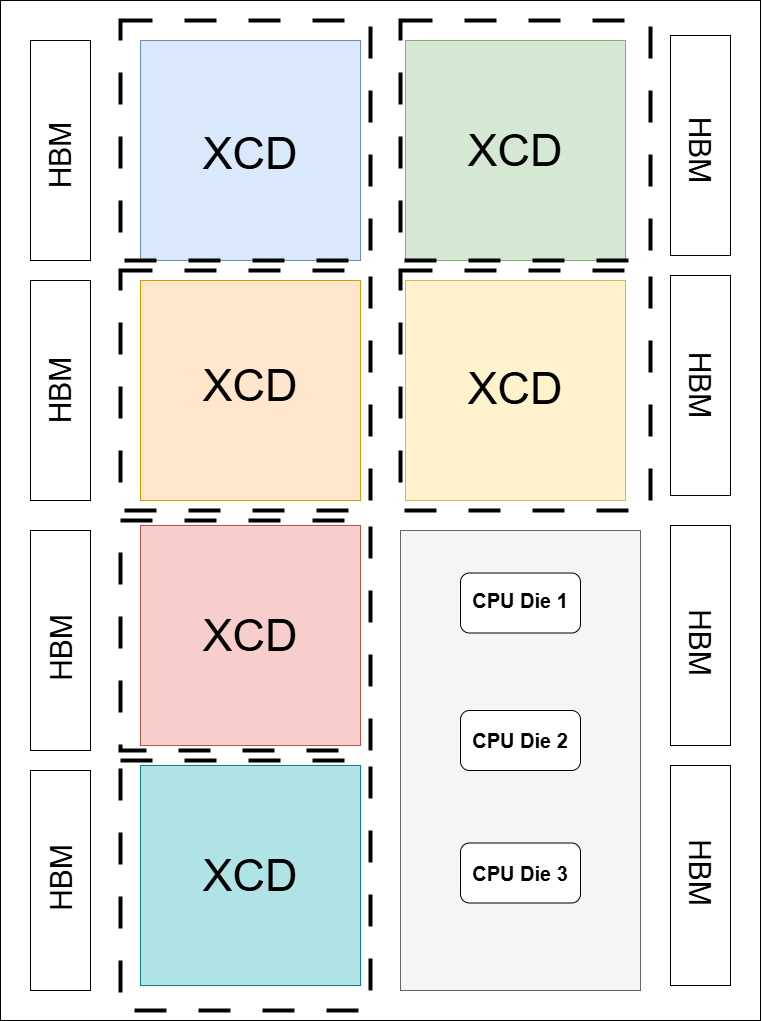
|
SPX: All 6 XCDs form a single device. |
CPX: Six partitions, one per XCD. |
Diagram Note: Dotted lines in the diagrams indicate compute partition boundaries.
b. Memory Partitioning (NPS1)#
The MI300A platform operates exclusively in NPS1 mode — or NUMA Per Socket — where all eight HBM stacks are uniformly interleaved and exposed as a unified memory pool. Unlike MI300X, MI300A does not support DDR memory.
Key Features of NPS1 Mode:
The entire 128GB of HBM is accessible across all partitions, regardless of compute mode (SPX, CPX).
Memory is interleaved across the eight HBM stacks to ensure maximum bandwidth and minimal latency.
No memory locality enforcement across partitions — partitions can transparently access the shared memory fabric.
Memory Mode |
Description |
Compatible Compute Modes |
|---|---|---|
NPS1 |
Interleaved HBM3 pool (128GB) accessible by all partitions |
SPX, CPX |
The tight integration of CPU and GPU with a unified cache-coherent memory fabric eliminates the complexity of NUMA-aware memory allocation typically required in multi-socket, discrete systems.
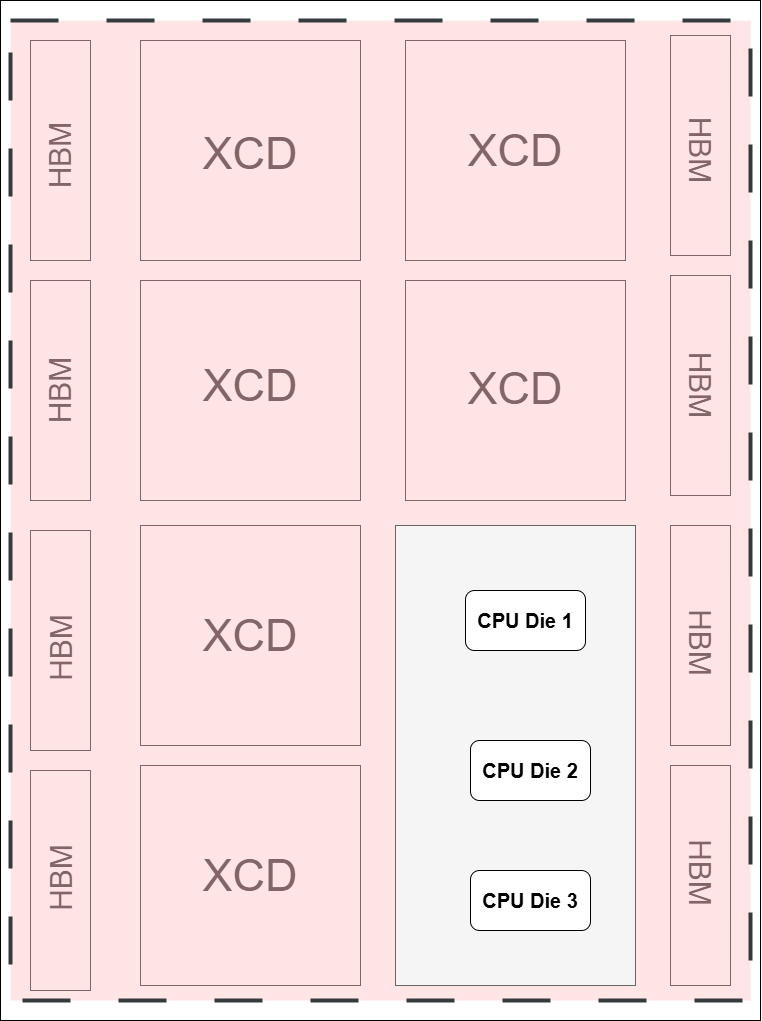
Diagram Note: All GPU partitions in SPX, and CPX share the same physical memory pool via the NPS1 model.
4. Benefits of Partitioning (MI300A APU)#
Partitioning in the MI300A APU—enabled via SPX, and CPX modes—offers a flexible architecture that balances unified memory access with compute isolation. These modes allow system architects to tune performance, resource efficiency, and workload isolation on heterogeneous CPU+GPU platforms.
CPX mode in MI300A enables fine-grained control over the GPU compute fabric by exposing each XCD as a distinct logical GPU. When paired with memory locality-aware execution, CPX mode enhances parallelism, isolation, and throughput for multi-user or multi-tenant systems, particularly in high-performance computing (HPC) and cloud-native inference environments.
TPX mode serves as a balanced hybrid mode, exposing 4 partitions with 2 XCDs each. This is especially beneficial for mid-sized models or workloads that demand more compute capacity and memory than a single XCD can provide, while still requiring workload separation. TPX enables optimal use of shared CPU and GPU resources, and aligns well with the shared-memory design of the MI300A APU.
Partitioning at the compute level enables dynamic workload management, where different applications or user sessions can be mapped to different GPU partitions, without interference or scheduling conflicts. This is a key enabler for simultaneous AI, HPC, and mixed-precision scientific workloads.
Memory-coherent interconnects in MI300A ensure that each partition can maintain high-bandwidth, low-latency communication with the CPU and system memory. Even when GPUs are logically isolated via CPX, partitions retain access to the shared HBM and DDR memory pools through the CPU’s memory controller, simplifying software complexity for multi-GPU workloads.
Partitioning also plays a crucial role in fault containment and serviceability. In the event of a GPU partition failure, workloads in other partitions can continue unaffected, enhancing system uptime and reducing recovery overheads.
Driver-level flexibility allows runtime switching between SPX, and CPX modes (subject to reboot in some configurations), enabling operators to adapt the system to workload needs without hardware reconfiguration.
On MI300A, GPU partitioning also interacts closely with HMM (Heterogeneous Memory Management) and Shared Virtual Memory (SVM), enabling user applications to seamlessly share pointers and memory structures across CPU and GPU partitions. This allows for a unified programming model that reduces developer complexity and increases code portability.
Note
On MI300A, while SPX remains the default mode, CPX offers compelling benefits for multi-process environments, scientific workflows, and latency-sensitive inference pipelines. Administrators should carefully benchmark their workloads across modes to identify the optimal configuration.