AMD Instinct MI300X GPU Partitioning Overview#
1. Introduction#
The AMD Instinct™ MI300X GPU represents a significant step forward in the design of modular, scalable GPU compute platforms. With its innovative architecture and ROCm software ecosystem, MI300X supports dynamic compute and memory partitioning. This capability enables developers and system administrators to treat a single GPU as multiple logical devices, allowing for efficient workload management, resource isolation, and performance tuning.
The MI300X GPU introduces advanced support for compute and memory partitioning, enabling high-performance computing (HPC), artificial intelligence (AI), and machine learning (ML) workloads to achieve fine-grained resource allocation and isolation.
Partitioning exposes internal GPU hardware components, specifically Compute Complexes (XCDs) and memory stacks (HBM) as discrete logical devices. This allows users to optimize system utilization, achieve better scheduling control, and tailor compute and memory resources to workload-specific requirements.
This guide provides a detailed overview of GPU partitioning modes, primarily CPX and NPS4 on bare-metal operating systems. It includes architectural background, partitioning use cases, configuration methods, and validation steps to ensure users can fully leverage MI300X’s capabilities.
2. GPU Architecture Summary#
The MI300X GPU is composed of modular chiplets, each optimized for compute or I/O tasks to achieve scalability and high-throughput performance. Key architectural components include:
XCD (Accelerator Complex Die): Compute element of the GPU, each XCD contains 38 Compute Units (CUs), responsible for executing parallel workloads.
IOD (I/O Die): Manages interconnects, memory, and data routing across the chiplets.
3D Stacking: Each pair of XCDs is 3D-stacked on a single IOD allowing for tight integration and low-latency interconnects.
HBM (High-Bandwidth Memory): MI300X includes 8 stacks of HBM, offering 192GB of unified memory.
Total GPU Configuration:
8 XCDs per GPU → 304 total CUs
4 IODs per GPU
8 HBM (High Bandwidth Memory) stacks (2 per IOD)
192GB of unified HBM capacity
This layout provides the foundation for partitioning, allowing resources to be split and exposed logically to the operating system and applications.
3. Partitioning Concepts#
a. Compute Partitioning (SPX, DPX, CPX)#
Compute partitioning (also referred to as MCP – Modular Chiplet Platform) is the division of the GPU’s compute and memory resources into smaller logical units, which can then be addressed as independent devices by applications. This is implemented in the driver layer and can be dynamically adjusted at runtime using command-line tools like amd-smi.
There are three key compute partitioning modes:
SPX (Single Partition X-celerator): Treats the entire GPU as a single device.
DPX (Dual Partition X-celerator): Exposes the GPU as two logical devices, each with 4 XCDs.
CPX (Core Partitioned X-celerator): Exposes each XCD as an individual logical GPU.
Key Benefits of Partitioning:
Supports workload isolation and parallelism.
Enables better scheduling granularity and performance tuning.
Facilitates resource sharing across users or processes in multi-tenant environments.
Partitioning Rules:
Partitions must include an even number of XCDs (e.g., 2, 4, 6, 8).
Partitioning is spatial: each partition is composed of physically grouped XCDs.
Compute partitioning is configured via the driver and hardware level, no VM (virtualization) or hypervisor required.
Partition Modes Comparison
Mode |
Logical Devices |
CUs per Device |
Memory per Device |
Best For |
|---|---|---|---|---|
SPX |
1 |
304 |
192GB |
Unified workloads |
DPX |
2 |
152 |
96GB |
Medium models, balanced multi-tenancy |
CPX |
8 |
38 |
24GB |
Isolation, fine-grained scheduling, small batch sizes |
i. SPX (Single Partition X-celerator)#
Default Mode for MI300X.
Treats all 8 XCDs as a single monolithic GPU.
All memory and compute resources are visible as one unified device.
Implicit synchronization across XCDs is handled by the hardware.
Use Case: Ideal for large-scale models or applications that require unified compute and memory access without needing explicit control over scheduling.
Behavior:
amd-smishows 1 GPU with 304 CUs and 192GB HBM.Workgroups are automatically distributed across all XCDs (round-robin).
The GPU will always revert back to this default SPX mode when the system is rebooted or when the amdgpu driver is unloaded and reloaded.
ii. DPX (Dual Partition X-celerator)#
Divides the GPU into 2 logical devices.
Each partition contains 4 XCDs (152 CUs per partition).
Each partition receives 96GB of HBM in default configuration.
Memory Allocation:
Compatible with NPS1, NPS2, and NPS4 memory modes (platform-dependent).
In NPS2, each DPX partition aligns with a memory quadrant for optimal memory locality.
Provides balance between full GPU utilization and workload isolation.
Use Case:
Medium-sized model deployment: Ideal for models that require more resources than a single XCD but don’t need the full GPU.
Balanced multi-tenancy: Run two isolated workloads with substantial resources each.
Development and testing: Partition GPU for parallel development workflows.
Behavior:
amd-smishows 2 GPUs, each with 152 CUs and 96GB HBM.Peer-to-Peer access between partitions available.
Workgroups distributed within each partition’s 4 XCDs.
iii. CPX (Core Partitioned X-celerator)#
Each XCD is represented as a separate logical GPU.
Offers granular control—each partition gets 38 CUs and 24GB of HBM.
Memory Allocation:
In NPS1, HBM memory is interleaved across all stacks.
In NPS4, each XCD gets a dedicated memory quadrant (2 HBM stacks) which can be used to interleave the 24GB of dedicated memory each XCD is given in this mode.
CPX works optimally with memory partitioning (NPS4)
Use Case:
Multi-Tenant Environments: Allocate separate GPU partitions to different users or tenants in a data center to achieve isolation.
Heterogeneous Workloads: Run AI training, inference, and HPC workloads simultaneously on different partitions where individual models/data fit within a single XCD’s memory.
Resource Oversubscription: Optimize resource usage by oversubscribing partitions for workloads with varying demands.
Behavior:
amd-smishows 8 GPUs, each with 38 CUs and 24GB HBM.Workgroups are explicitly launched to a specific XCD (i.e., scheduling can be controlled at the application level).
Peer-to-Peer (P2P) access between XCDs is available and can be enabled.
MI300X SPX |
MI300X CPX |
|---|---|
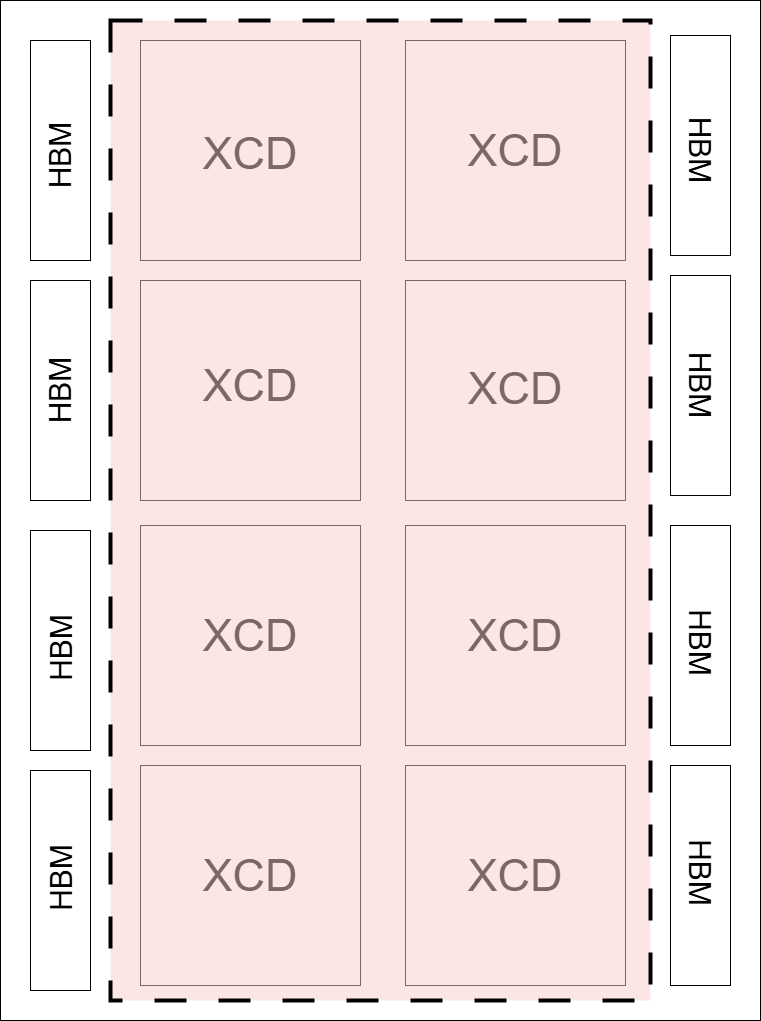
|
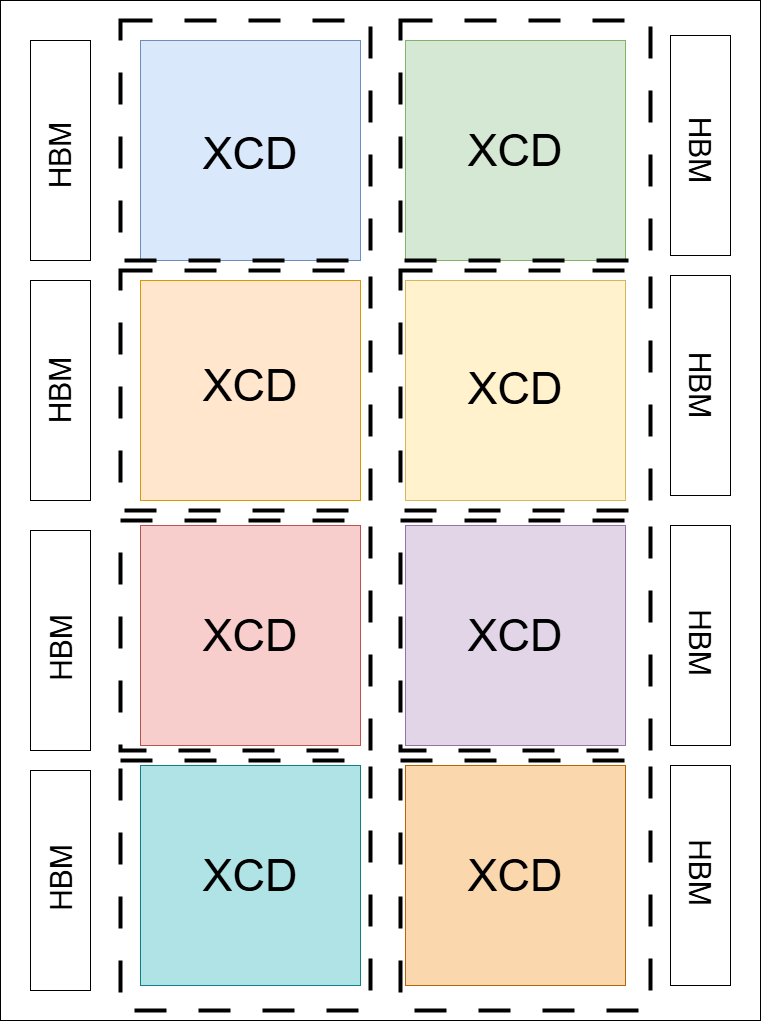
|
SPX: All XCDs appear as one logical device. |
CPX: Each XCD appears as one logical device. |
Diagram Note: Dotted lines in the diagrams indicate compute partition boundaries.
b. Memory Partitioning (NPS)#
The memory partitioning modes (known as Non-Uniform Memory Access (NUMA) Per Socket (NPS)) change the number of NUMA domains that a device exposes, which define how HBM (High Bandwidth Memory) is allocated and exposed to logical devices.
Memory partitioning in the MI300X series involves dividing the total memory, specifically HBM stacks, which are accessible to a compute unit, into partitions.
This is configured as application memory for XCDs, allowing for more efficient memory management and allocation.
The memory partitioning is done at the hardware level, and the driver manages the visibility of these partitions to the operating system and applications.
In MI300X, the number of memory partitions must be less than or equal to the number of compute partitions.
The MI300X supports two memory partitioning modes:
NPS1 (Unified Memory):
All 8 HBM stacks are viewed as one unified memory pool and is accessible to all XCDs.
amd-smi will show 1 device with 192GB of HBM.
Memory is allocated interleaved across all HBM stacks.
Best for workloads requiring unified memory.
Compatible mode with SPX and CPX.
NPS2 (Dual Memory Partition):
Divides HBM into 2 memory partitions of 96GB each.
Each memory partition is accessible to the logical devices in its partition.
Compatible with DPX mode, providing optimal memory locality for dual-partition workloads.
NPS4 (Partitioned Memory):
Pairs of HBM stacks forming 48GB each are viewed as separate memory partitions. Each CPX partition still only has access to 24GB of HBM memory, but the memory is interleaved across this 48GB memory partition instead of across the entire 192GB of the GPU.
Each memory quadrant (partition) of the memory is directly visible to the logical devices in its quadrant.
An XCD can still access all portions of memory through multi-GPU programming techniques.
Best for workloads requiring dedicated memory resources.
Only available with CPX mode.
In NPS4 mode, the traffic latency to HBM (High Bandwidth Memory) is minimized because it remains on the same AID (Accelerator Interface Domain), leading to shorter latency and faster transitions from idle to full bandwidth.
In NPS4 mode, higher bandwidth to MALL (Memory Attached Last Level Cache) can be achieved.
In most cases, NPS4 mode is highly performant when paired with CPX mode for workloads that fit within the memory capacity of a single XCD.
Memory Mode |
Description |
Compute Mode Compatibility |
|---|---|---|
NPS1 |
Unified memory pool (192GB) |
SPX, DPX, CPX |
NPS2 |
2 memory partitions (96GB each) |
DPX |
NPS4 |
4 memory partitions (48GB each). Note- Each CPX only accesses 24GB from the partition. |
CPX only |
MI300X NPS1 |
MI300X NPS4 |
|---|---|
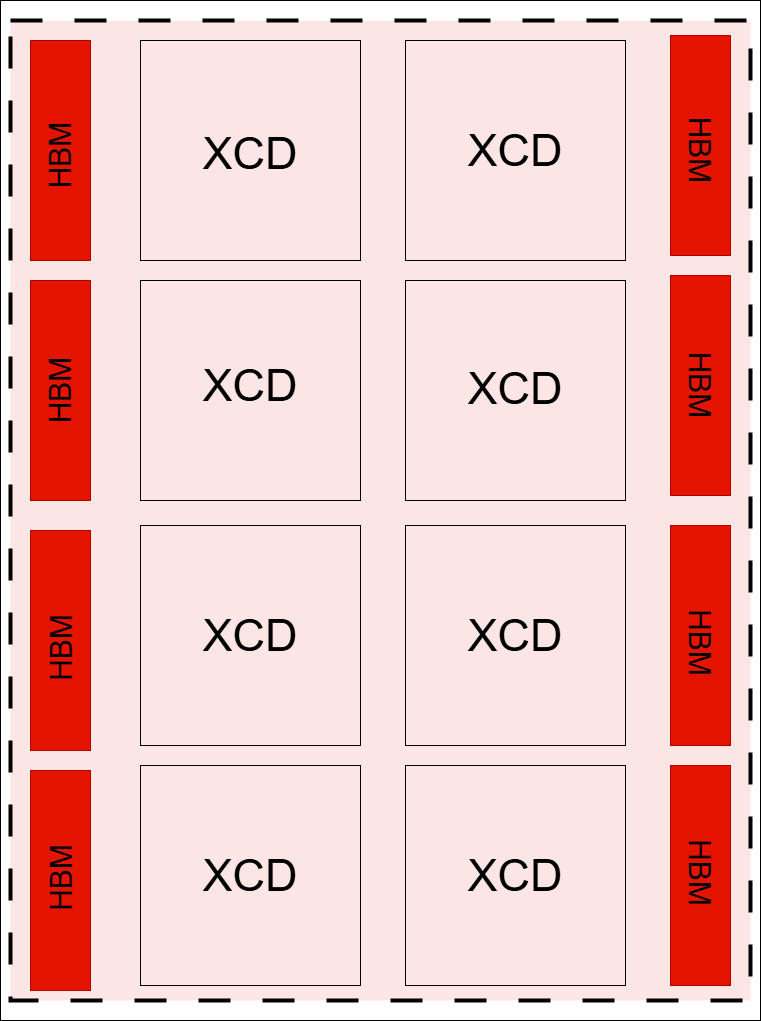
|
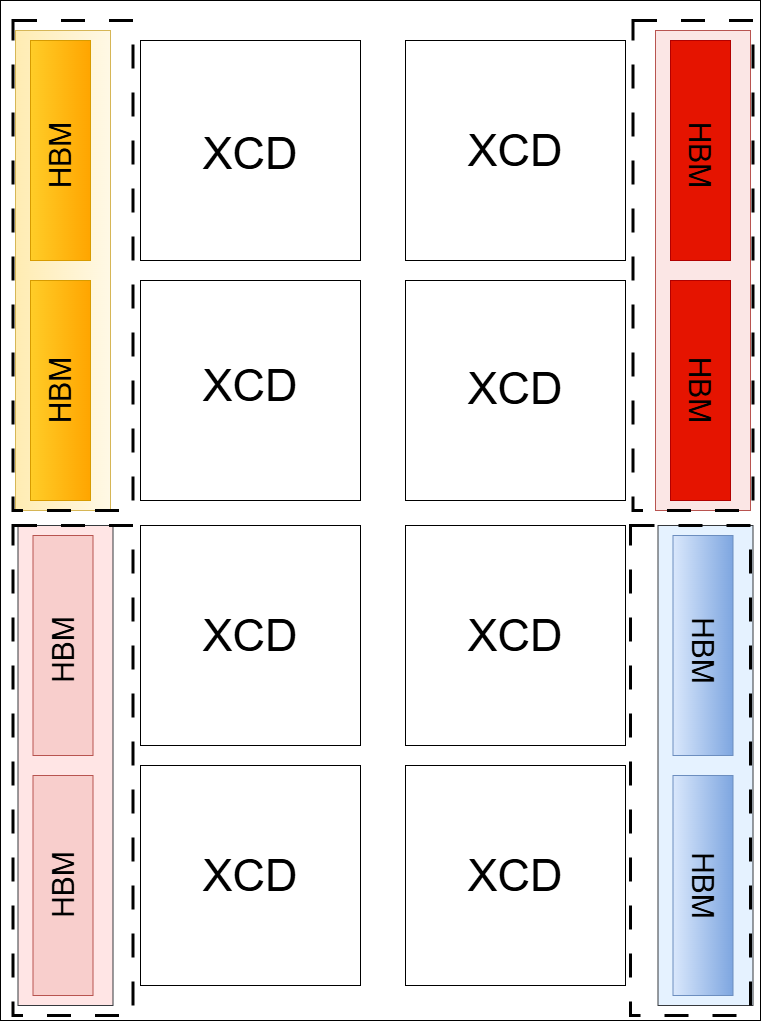
|
NPS1: All HBM stacks appear as a unified memory pool. |
NPS4: HBM stacks are segmented into memory quadrants. |
Diagram Note: Dotted lines in the diagrams indicate memory partition boundaries.
4. Benefits of Partitioning#
Partitioning support in the AMD Instinct™ MI300X GPU delivers significant operational and performance advantages in large-scale AI inference and HPC environments. By logically segmenting GPU and memory resources, users can achieve fine-grained workload control, reduce overhead, and boost cluster utilization.
Key benefits of partitioning on MI300X include:
Improved performance for small to mid-sized language models: Partitioning the MI300X into four logical CPX GPUs (via SPP=CPX and NPS=4) allows small models (≤13B parameters) to run independently within each GPU slice. This enables higher concurrency and throughput when serving multiple models simultaneously, especially in VLLM-based inference engines.
Enhanced communication efficiency for distributed workloads: CPX + NPS4 mode aligns well with multi-GPU collective communication patterns, delivering improved bandwidth and reduced latency for all-to-all and all-reduce operations through optimized ROCm Communication Collectives Library (RCCL) backend.
Power savings and thermal optimization: Memory partitioning with NPS=4 reduces the power consumed by the HBM3 memory stacks per workload, enabling energy-efficient inference and better thermal headroom under dense workloads.
Dynamic resource provisioning and flexibility: Partitioning enables runtime configuration of compute and memory without requiring a full system reboot. This supports agile scheduling, workload isolation, and high system uptime in shared or multi-tenant data center environments.
Improved workload packing and density: Logical GPU slicing allows simultaneous deployment of multiple containerized inference services per MI300X GPU. This leads to higher resource utilization and better GPU consolidation ratios when compared to monolithic deployments.
Note
Mixed memory partitioning modes (e.g., combining NPS1 and NPS4) are not recommended for single-node configurations due to potential performance and synchronization issues across NUMA domains.